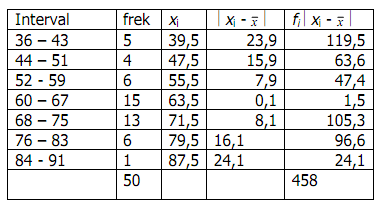
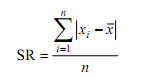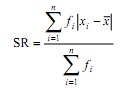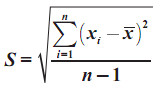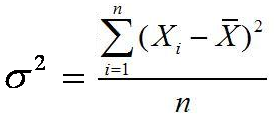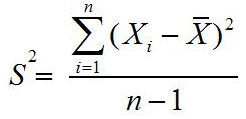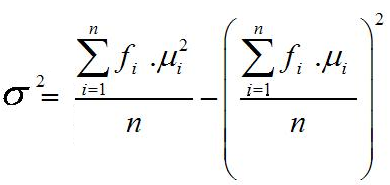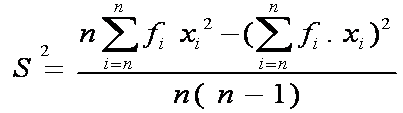Ukuran Pemusatan
Agar penyajian
kumpulan data lebih mudah dipahami,statistika menyediakan metode penyusunan
data dalam bentuk distribusi frekuensi,tapi distribusi frekuensi yang terbentuk
masih mengandung banyak elemen. Padahal informasi yang kita dapatkan dari data
akan lebih mudah dipahami agar dapat diwakili oleh satu nilai saja. Dalam statistika dikenal beberapa macam
ukuran nilai pusat. Yang paling banyak digunakan adalah rata-rata hitung (Arithmatic mean),Median,Modus,Rata-rata
tertimbang,rata-rata ukur,dan lain-lain.
a.
Pengertian Mean
Menurut
Sudijono, Anas (2008:79), secara singkat pengertian tentang Mean dapat
dikemukakan sebagai berikut: Mean
dari sekelompok (sederetan) angka (bilangan) adalah jumlah dari keseluruhan
angka (bilangan) yang ada, dibagi dengan kebanyakan angka (bilangan)
tersebut.
Untuk lebih jelasnya dapat
dikemukakan contoh sebagai berikut: Misalnya seorang Siswa Madrasah Aliyah
memiliki nilai hasil ulangan dalam bidang studi Matematika, Pendidikan
Kewarganegaraan, Bahasa Indonesia, Bahasa Inggris, Ilmu Pengetahuan Sosial dan
Ilmu Pengetahuan Alam berturut-turut: 8, 9, 7, 4, 6, dan 5. Untuk memperolah
Mean nilai hasil ulangan tersebut, keenam butir nilai yang ada itu kita
jumlahkan, lalun kita bagi dengan banyaknya nilai tersebut, yaitu: (8 + 9 + 7 +
4 + 6 + 5) : 6 atau
= 6,50
Jika keenam bilangan tersebut kita
lambangkan dengan
,
,
,
,
dan
, sedangkan
banyaknya nilai itu kita lambangkan dengan N, maka Mean dari keenam butir nilai
tersebut adalah :
=
Apabila kita
rumuskansecara umum, maka:
=
Atau dapat disingkat menjadi:
=
Inilah
rumus umum atau rumus dasar untuk mencari atau menghitung Mean. Sudijono, Anas
(2008:76).
a.
Pengertian Nilai Rata-rata Pertengahan (Median)
Menurut Sudijono, Anas
(2008:93), yang dimaksud dengan Nilai Rata-rata Pertengahan atau Median adalah
suatu nilai atau suatu angka yang membagi suatu distribusi data ke dalam dua bagian yang sama
besar. Dengan kata lain, Nilai Rata-rata Pertengahan atau Median adalah nilai
atau angka yang di atas nilai atau angka tersebut terdapat 1/2N dan dibawahnya
juga terdapat 1/2N. Itulah sebabnya Nilai Rata-rata ini dikenal sebagai Nilai
Pertengahan atau Nilai Posisi Tengah, yaitu nilai yang menunjukkan pertengahan
dari suatu distribusi data.
Disini pun kita berhadapan dengan dua kemungkinan,
yaitu: (1) data tunggal yang seluruh skornya berfrekuensi 1, number of
cases-nya merupakan bilangan gasal (ganjil), dan (2) data tunggal yang seluruh
skornya berfrekuensi itu, number of cases-nya merupakan bilangan genap ( bukan
bilangan gasal).
(i)
Mencari
nilai rata-rata pertengahan untuk data tunggal yang seluruh skornya berfrekuensi 1 dan number of
caess-nya berupa bilangan gasal.
Untuk data tunggal yang seluruh skornya
berfrekuensi 1 dan number of cases-nya bilangan gasal (yaitu: M = 2m + 1 ),
maka median data yang demikian itu terletak pada bilngan yang ke (n+1).
contoh
: 9 orang mahasiswa menempuh ujian lisan dala mata kuliah teknik evaluasi
pendidikan. Niali mereka adalah sebagai berikut: 65 75 60 70 55 50 80 40 30.
Untuk mengetahui nilai berapakah yang merupakan Nilai Rata-rata Pertengahan
atau Median dari kumpulan nilai hasil ujian tersebut, pertama-tama deretan itu
kita atur mulai dari nilai terendah sampai nilai tertinggi:
30 40 50 55 60 65 70 75 80
kita
lihat dalam deretan nilai di atas, bilangan ke-1 adalah 30, bilangan ke-2 = 40,
bilangan ke-3 = 50, bilangan ke-4 = 55, bilangan ke-5 = 60, bilangan ke-6 = 65,
bilangan ke-7 = 70, bilangan ke-8 = 75 dan bilangan ke-9 = 80. Karena N = 9,
sedang rumus bilangan gasal adalah: N = 2n +1, maka 9 = 2n + 1
9 = 2n + 1
9 – 1 = 2n
n = 4
dengan demikian nilai yang merupakan nilai rata-rata
pertengahan atau median dari nilai hasil ujian lisan tersebut adalah nilai (
bilangan)
yang ke- ( 4 + 1 ) atau bilangan ke-5, yaitu nilai 60
(i)
Mencari Nilai Rata-rata Pertengahan
untuk Data Tunggal yang seluruh skor-nya berfrekuensi 1, dan Number of
Cases-nya berupa bilangan genap
Untuk
data tunggal dan seluruh skornya berfrekuensi 1 dan Number of Cases-nya
merupakan bilangan genap (yaitu: N=2n), maka Median atau Nilai Rata-rata
Pertengahan data yang demikian itu terletak antara bilangan yang ke-n dan
ke-(n+1).
Contoh
: tinggi badan 10 orang calon yang mengikuti tes seleksi penerimaan calon
penerbang, menunjukkan angka sebagai berikut: 168 162 169 170 164 167 161 166
163 dan 165 cm.
cara
mencari Nilai Rata-rata Pertengahan atau Mediannya sama seperti telah dikemukakan
di atas, yaitu pertama-tama deretan angka itu terlebih dahulu kita atur
berderet, mulai dari nilai terendah sampai nilai tertinggi.
Karena
N = 10 (merupakan bilangan bulat), sedang rumus untuk bilangan bulat adalah : N
= 2n, maka : 10 = 2n , n
= 5
Jadi
Median atau Nilai Rata-rata Pertengahan dari tinggi badan 10 orang peserta tes
seleksi Calon Penerbang itu terletak antara bilangan ke-5 dann ke (5+1), atau
antara bilaangan ke-5 dan ke-6. Dalam deretan angka-angka di atas, bilangan
ke-5 adalah 165, sedang bilangan ke-6 adalah 166.
Jadi Mdn =
=
165,50
. Modus (Mode)
a. Pengertian
Modus
Menurut
Sudijono, Anas (2008:105), modus umunya dilambangkan dengan Mo. Modus tidak
lain adalah suatu skor atau nilai yang mempunyai frekuensi paling banyak;
dengan kata lain, skor atau nilai yang memiliki frekuensi maksimal dalam
distribusi data.
b. Cara Mencari Modus
1) Cara Mencari Modus
untuk Data Tunggal
Mencari modus untuk data tunggal dapat dilakukan
dengan mudah dan cepat; yaitu hanya dengan memeriksa (mencari) mana di antara
skor yang ada, yang memiliki frekuensi terbanyak. Skor atau nilai yang memiliki
frekuensi terbanyak itulah yang kita sebut Modus.
Contoh: Misalkan data tentang
data 50 orang Guru Matematika yang tercantum pada tabel 3.7 dapat kita cari
Modusnya sebagai berikut:
Tabel3.9. Tabel Distribusi Frekuensi untuk Mencari
Modus dari Data yang Tertera Pada Tabel 3.7.
|
Usia (x)
|
f
|
|
31
30
29
28
Mo (27)
26
25
24
23
|
4
4
5
7
(12)= f maksimal
8
5
3
2
|
|
Total
|
50=N
|
Modus untuk data di atas adalah usia 27 tahun.
Mengapa demikian? Sebab dari sejumlah 50 orang Guru Matematika tersebut, yang
paling banyak adalah berusia 27 tahun.
.
Kuartil, Desil,
Persentil
Jika sekumpulan data dibagi menjadi
empat bagian yang sama banyak, sesudah disusun menurut urutan nilainya , maka
bilangan membaginya disebut kuartil. Ada tiga buah kuartil, ialah kuartil
pertama, kuartil kedua, kuartil ketiga yang masing-masing disingkat Q1
, Q2, dan Q3 . pemberian nama ini, dimulai dari nilai
kuartil paling kecil. Untuk menentukan nilai kuartil caranya adalah :
1.
Susun data menurut urutannya
2.
Tentukan letak kuartil
3.
Menentukan nilai kuartil
Letak
kuartil ke-i diberi lambing K1 , ditentukan oleh rumus :
Letak
Ki= data ke
Dengan
i=1,2,3
Contoh
: sampel dengan data 75,82, 66,57, 64,56, 92,94, 86,52,60,70. Setelah disusun
menjadi 52,56,57,60,64,66,70,75,82,86,92,94.
Letak
K1= data ke
=
data ke 3
,
yaitu antara data ke -3 dan data ke-4
Nilai
K1= data ke-3 +
(data ke-4 – data ke-3)]
K1= 57 +
(60 – 57) = 57
Letak
K3= data ke
=
data ke 9
K3= data ke-9 +
(data ke-10 – data ke-9)
K3 =82 +
(86-82) =85
Untuk
data yang telah disusun dalam daftar distribusi frekuensi, Kuartil dihitung
dengan rumus :
Qi
= b + p (
)
Dengan
i = 1,2,3
Dengan
b = batas bawah kelas Ki , ialah kelas interval dimana Ki
terletak
P = panjang kelas Ki
F
= jumlah frekuensi dengan tanda kelas lebih kecil dari tanda kelas Ki
F
= frekuensi kelas Ki
Kembali
pada hasil ujian 80 mahasiswa seperti dalam tabel di bawah ini , maka untuk
menentukan kuartil ketiga ,
x 80 = 60 data . b = 80.5 ;p=10; f=20; F=48. Dengan i=3 dan n=80 maka
K3
= 80.5 + 10(
)
K3
= 86.5
Tabel
hasil ujian 80 mahasiswa
|
Nilai Ujian
|
fi
|
|
31-40
41-50
51-60
61-70
71-80
81-90
91-100
|
1
2
5
15
25
20
12
|
|
Jumlah
|
80
|
Ini
berarti ada 75% mahasiswa yang mendapat nilai ujian paling tinggi 86.5
sedangkan 25% lagi mendapat nilai paling
rendah.
Jika
kumpilan data itu dibagi menjadi 10 bagian yang sama maka didapat Sembilan
pembagi dan setiap pembagi dinamakan desil. Kerananya ada sembilan buah desil,
ialah desil pertama, desil kedua,…., desil kesembilan yang disingkat dengan d1,,
d2,…,d9 . desil-desil ini dapat ditentukan dengan jalan :
1.
Susun data menurut susunan nilainya
2.
Tentukan letak desil
3.
Tentukan nilai desil
Letak
desilke-I diberi lambing di , ditentukan oleh rumus :
Letak
d1 = data ke
Dengan
i=1,2,…,9
Contoh
: untuk data yang disusun dalam contoh terdahulu, ialah :
52,56,57,60,64,66,70,75,82,86,92,94, maka letak
d7 = data ke
=
data ke-9,1
Nilai
d7 = data ke-9 + (0,1) (data ke-10 – data ke-9)
d7
= 82 + (0,1)(86-82) = 82,4
untuk
data dalam distribusi frekuensi
di = b + p (
)
dengan
i=1,2,…,9
dengan
b = batas bawah kelas di , ialah kelas interval dimana di
akan terletak
P = panjang kelas di
F
= jumlah frekuensi dengan tanda kelas lebih kecil dari tanda kelas di
F
= frekuensi kelas di
Jika
diminta d3 unuk 80 nilai ujian statistika, maka kita perlu 30% x 80
= 24 data. b=60.5; p=10; f=15; F=8 .dengan i=3 dan n=80, maka didapat
d3
= 60.5 + 10(
)
d3
= 71,2
Jika
sekumpulan data tersebut dibagi menjadi 100 bagian yang sama akan menghasilkan
99 pembagi yang dinamakan persentil yang dilambangkan dengan P.
Letak Persentil Pi untuk sekumpulan
data ditentukandengan rumus :
Pi
= data ke
dengan
i=1,2,…,99
sedangkan
nilai Pi untuk data dalam daftar distribusi frekuensi dihitung
dengan :
Pi = b + p (
)
dengan
i=1,2,…,99
dengan
b = batas bawah kelas Pi , ialah kelas interval dimana Pi
terletak
P = panjang kelas Pi
F
= jumlah frekuensi dengan tanda kelas lebih kecil dari tanda kelas Pi
f
= frekuensi kelas Pi
DAFTAR PUSTAKA
Sudijono, Anas. 2009. Pengantar
Statistik Pendidikan. Jakarta :PT Raja Grafindo Persada
Sudjana. 2002.Metoda Statistika.Bandung : TARSITO
Harahap, B. dan ST.
Negoro.1998. Ensiklopedia Matematika. Ghalia Indonesia
Dajan, Anto.1986. Pengantar Metode Statistik Jilid I. Jakarta :LP3ES